






In the previous post, we examined the Full Page Handwriting Recognition (Full Page HTR) problem faced by Turnitin, noted that it is far greater in scope than classical Handwritten Text Recognition (HTR) and limitations of the typical approach to solving it. In this post, we present our approach and the AI model we created and deployed to solve this problem.
Model ArchitectureIn view of the problems mentioned in our previous post (and already having previously developed a system with the classical approach), we designed a novel Neural Network (Deep Learning) model that takes in an image and emits text. None of the steps needed to go from image to transcription are hand-crafted; the model learns them all via Machine Learning. Adapting the model to a new dataset or adding new capabilities is just a matter of retraining or fine-tuning with different labels or different data.
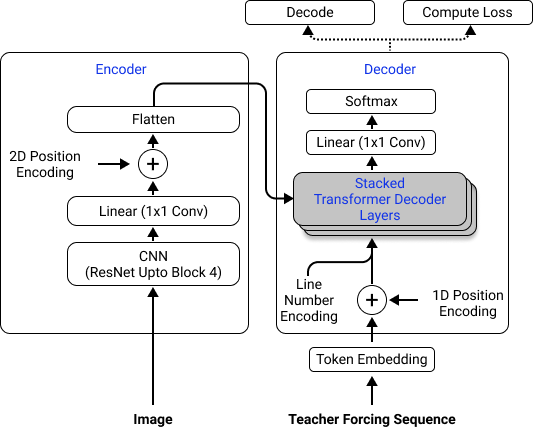
Figure 2 shows our Neural Network architecture. It consists of a Convolutional Neural Network-based encoder and a Transformer-based decoder. The main advantage of such an End-to-End Machine Learning (ML) approach is that it is completely data-driven and therefore the model can be easily changed by retraining it with a different data set and/or objective. For example, we could add new languages, new auxiliary tasks, or even new types of text like math markup (Latex).
Another advantage of this architecture is that it draws from ideas developed in the field of general AI as opposed to being a bespoke HTR solution. These ideas are equally applicable across modalities and domains (vision, NLP, speech, video, genomics etc.) thus making this design that much more resilient to future changes in application. It is implemented using PyTorch. For those interested, details are provided in our research paper (get the preprint here).
Needless to say, with an End-to-End ML model like ours, the training data is crucial - specifically, the model needs to be trained on data at least as varied as expected in service.
Data Labeling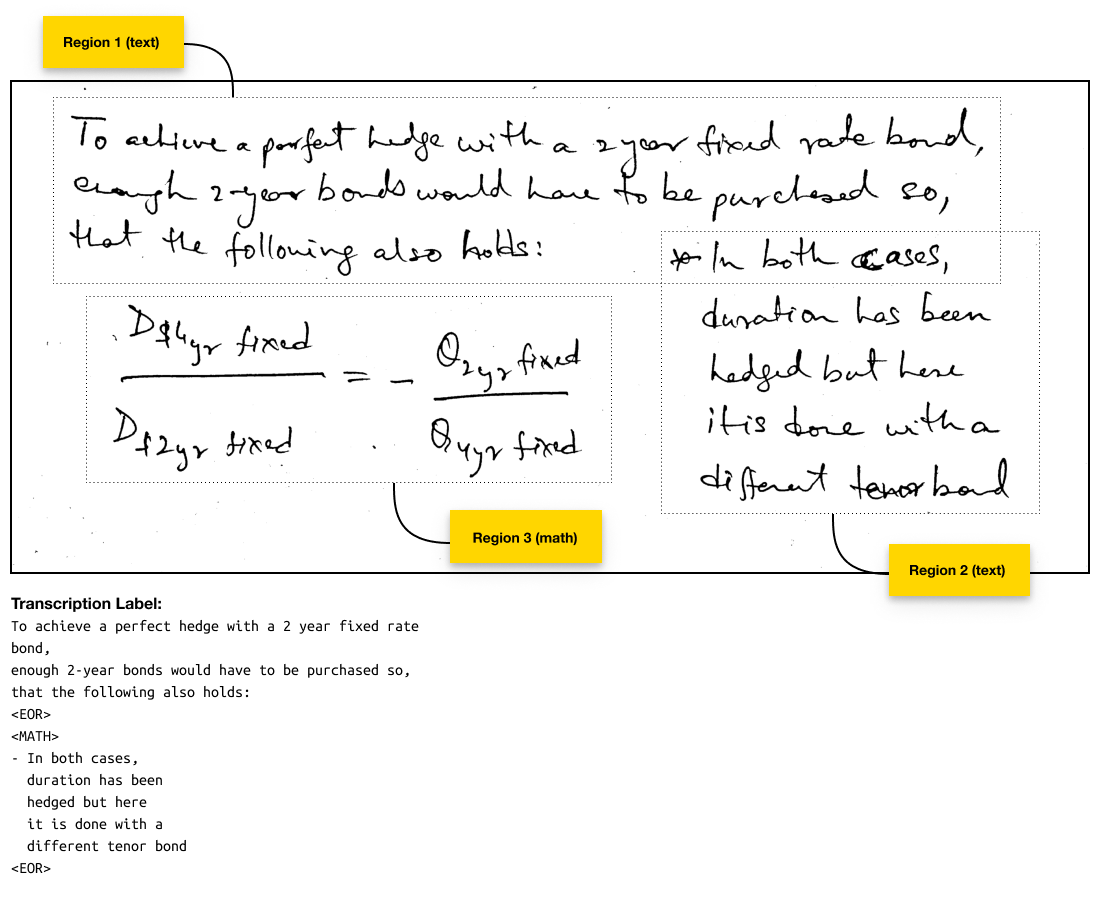
We had labeled single line crops from our previous model but those weren’t sufficient for an end-to-end model. We needed (images of) full passages of text labeled, not just with their textual transcriptions, but also with all the additional semantic markup. So, we executed a mini-project in order to get the images annotated appropriately. We conducted a thorough analysis of the images the model was expected to encounter and came up with a set of rules/guidelines for annotation. Additionally, a web-app was developed that would enable said annotation effort. An example annotation is shown in Figure 3.


The handwriting data was enhanced with synthetically generated images, which we created by rendering random spans from Wikipedia Text using 100+ fonts. The samples vary in image size, text length, orientation, text alignment, and placement on canvas. The fonts are a mix of print and cursive types. While this dataset trains the model to recognize print fonts, it also enhances the model’s language skills by exposing it to new subjects (and possibly languages) not present in the handwritten data. For example, if we wanted to enhance the model’s performance on chemistry terms, we needn’t look for a labeled dataset of chemistry text images; rather, we could just enhance the WikiText data with chemistry text and retrain the model. The model would learn to recognize handwriting from the existing non-chemistry handwriting data but would learn about chemistry words and how they are used in sentences (a.k.a Language Model) from the synthetic data.
We ended up combining the synthetic dataset with three that we annotated from Gradescope submissions. Further, since handwriting data is scarce, we artificially increase it by stitching together images of short spans of text into passages. Hence a majority of our training images end up being constructed on the fly rather than being picked from a static dataset. This significantly increases the overall dataset size which significantly improves the model’s performance on unseen data i.e., generalization;1 even turning out to be crucial in some cases. We also perform a variety of image augmentations - distortions and noise addition - again, in order to increase the variety of examples the model sees during training. This, broadly, falls under regularization techniques. Lastly, we create each training mini-batch on the fly, randomly sampling from all possible variations in data and augmentations. This keeps the training gradients as “true” as possible at each step. The model is implemented using PyTorch and takes a few days to learn on 8 GPUs.
ConclusionOur model beat the performance of text-recognition Cloud APIs available from all major vendors by a comfortable margin (our error rate on Gradescope data is 7.6% vs 14.4% of the best available API). We have also compared it with published State of Art results and to our knowledge, it is the best known full-page handwriting recognition model at this time (our error rate on a commonly-used academic challenge dataset called IAM is 6.3% vs 16.2% of the state of art full-page recognition model). Find full details in our research paper. That said, we do not consider the problem fully solved until the error rate has been brought down to under 1%. Some more work still remains to be done by the research community.
Our work does not end with deploying the model. Once deployed and processing new user data--data that, by definition, we have never seen before--we must watch its performance and remain alert for signs of trouble. This will be the subject of an upcoming blog post about Machine Learning Monitoring, a part of AI product development that is largely under-appreciated and under-developed.
- Generalization is the model’s ability to adapt properly to new, previously unseen data. It is a crucial ability because the model will only encounter unseen data when put into production.